
فرض کنید به عنوان یک مهندس ترافیک با بالا بودن سرعت متوسط خودروها در یک معبر رو به رو هستید. از شما خواسته می شود تا راهکارهایی ارائه دهید تا سرعت در این معبر کاهش یابد. شما در قدم اول در یک برداشت میدانی سرعت متوسط کنونی را اندازه گیری می کنید که در اینجا آن را ( ) می نامیم. سپس راهکارهایی از قبیل نصب تابلوی محدودیت سرعت و استفاده از سرعت گیر را پیشنهاد کرده و آنها را اجرا می کنید. پس از آن مجددا سرعت متوسط (
) می نامیم. سپس راهکارهایی از قبیل نصب تابلوی محدودیت سرعت و استفاده از سرعت گیر را پیشنهاد کرده و آنها را اجرا می کنید. پس از آن مجددا سرعت متوسط ( ) را برداشت می کنید. حال سوالی که پیش می آید این است که آیا پس از عملیاتی شدن راهکارهای ارائه شده، سرعت متوسط کاهش یافته است. برای پاسخ دادن به این سوال از آزمون های فرضیه استفاده می شود که در ادامه به بررسی آن می پردازیم و مفاهیم مرتبط با فرض های آماری، سطوح معناداری و P-value را مورد بررسی قرار می دهیم.
) را برداشت می کنید. حال سوالی که پیش می آید این است که آیا پس از عملیاتی شدن راهکارهای ارائه شده، سرعت متوسط کاهش یافته است. برای پاسخ دادن به این سوال از آزمون های فرضیه استفاده می شود که در ادامه به بررسی آن می پردازیم و مفاهیم مرتبط با فرض های آماری، سطوح معناداری و P-value را مورد بررسی قرار می دهیم.
فرض های آماری:
فرض صفر (( ) Null hypothesis) فرضی است که نشان می دهد هیچ تفاوتی بین گروه های مورد مطالعه وجود ندارد. در مثال مطرح شده به معنای این می باشد که سرعت متوسط قبل و بعد از عملیاتی شدن راهکارهای کاهش سرعت تفاوتی نکرده است.
) Null hypothesis) فرضی است که نشان می دهد هیچ تفاوتی بین گروه های مورد مطالعه وجود ندارد. در مثال مطرح شده به معنای این می باشد که سرعت متوسط قبل و بعد از عملیاتی شدن راهکارهای کاهش سرعت تفاوتی نکرده است.

به صورت پیش فرض، فرض بر این است که فرض صفر معتبر می باشد و سعی بر آن است تا با جمع آوری اطلاعات لازم این فرض رد شود.
فرض جایگزین (( ) Alternate Hypothesis) فرضی است که بیان کننده وجود تفاوت بین گروه های مورد مطالعه است. در مثال مطرح شده، فرض جایگزین نشان دهنده به وجود آمدن تفاوت در سرعت متوسط بعد از اعمال تغییرات است. در این مثال می توانیم فرض جایگزین را به دو صورت تعریف کنیم. در حالت اول سرعت ها با هم برابر نیستند و در حالت دوم سرعت پس از اعمال تغییرات کاهش یافته است.
) Alternate Hypothesis) فرضی است که بیان کننده وجود تفاوت بین گروه های مورد مطالعه است. در مثال مطرح شده، فرض جایگزین نشان دهنده به وجود آمدن تفاوت در سرعت متوسط بعد از اعمال تغییرات است. در این مثال می توانیم فرض جایگزین را به دو صورت تعریف کنیم. در حالت اول سرعت ها با هم برابر نیستند و در حالت دوم سرعت پس از اعمال تغییرات کاهش یافته است.


هر زمان که سعی بر رد کردن یا پذیرفتن فرض ها داشته باشیم، این امکان وجود دارد که دچار اشتباه شویم و دو خطای عمده زیر اتفاق بیافتد.
فرض صفر به اشتباه، رد شود. با توجه به اینکه فرض صفر بیان کننده عدم وجود تفاوت است، وقوع این خطا بیان می کند که بین گروه های مورد مطالعه تفاوت وجود دارد، در حالی که بین آنها تفاوتی نیست. در مثال مطرح شده رد کردن فرض صفر به معنای پذیرفتن این است که سیاست های اعمال شده برای کاهش سرعت اثرگذار بوده و سرعت ها متفاوت شده است. این خطا را خطای نوع اول می نامند و آن را با  نشان می دهند.
نشان می دهند.
فرض صفر به اشتباه، رد نشود. این به این معناست که زمانی که می بایست فرض صفر رد شود، به اشتباه پذیرفته شده است و در حالیکه بین گروه های مورد مطالعه تفاوت وجود دارد، به اشتباه می پذیریم که بین آنها تفاوت وجود ندارد. وقوع این خطا در مثال مطرح شده نشان می دهد که راهکار های اعمال شده برای کاهش سرعت موثر نبوده است. این خطا را خطای نوع دوم می نامند و آن را با  نشان می دهند.
نشان می دهند.
سطح معنی داری:
سطح معنی داری () در واقع میزان خطایی است که در رد کردن فرض صفر مرتکب می شویم. به عنوان مثال اگر سطح معنی داری را 5 درصد در نظر بگیریم، به این معناست که تا 5 درصد مواقع اشتباه رد شدن فرض صفر را می پذیریم.
P-value:
هنگام بررسی داده ها این احتمال وجود دارد که تحلیل های ما نسبت به فرض های مطرح شده دارای سو گیری باشد. در مثال مطرح شده در بالا، این امکان وجود دارد که تحلیل ها به صورتی انجام شود که نشان دهنده وجود تغییرات در سرعت (در اینجا کاهش سرعت) پس از سرمایه گذاری های انجام شده باشد. در این مثال تفاوت سرعت برداشت شده در مطالعه قبل و بعد ( ) می تواند دو حالت داشته باشد. این تفاوت می تواند واقعی باشد و یا صرفا یک نویز تصادفی باشد که ناشی از ناکافی بودن نمونه های جمع آوری شده است. برای پی بردن به اینکه کدام یک از این دو مورد صحیح است، از (P-value) استفاده می کنیم.
) می تواند دو حالت داشته باشد. این تفاوت می تواند واقعی باشد و یا صرفا یک نویز تصادفی باشد که ناشی از ناکافی بودن نمونه های جمع آوری شده است. برای پی بردن به اینکه کدام یک از این دو مورد صحیح است، از (P-value) استفاده می کنیم.
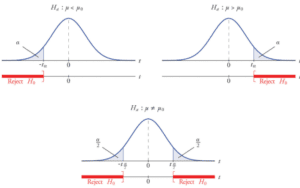
P-value به ما می گوید که با فرض درست بودن فرض صفر، احتمال مشاهده داده ها به چه شکل است. برای فهم بهتر به شکل زیر که توزیع نرمال را نشان می دهد، دقت کنید. اگر سطح معنی داری را 0.05 در نظر بگیریم، 95 درصد داده ها در بازه بین ![\displaystyle [-1.96,1.96]](https://thep.ir/wp-content/ql-cache/quicklatex.com-16187e7037c54d7b89672484ca21d77a_l3.svg "Rendered by QuickLaTeX.com") قرار می گیرند. با فرض برقرار بودن فرض صفر، اگر داده ای در این بازه قرار بگیرد (
قرار می گیرند. با فرض برقرار بودن فرض صفر، اگر داده ای در این بازه قرار بگیرد ( )، تعجب آور نیست. اما اگر داده ای در خارج از محدوده یاد شده قرار بگیرد (
)، تعجب آور نیست. اما اگر داده ای در خارج از محدوده یاد شده قرار بگیرد ( )، نیاز به بررسی بیشتر دارد.
)، نیاز به بررسی بیشتر دارد.
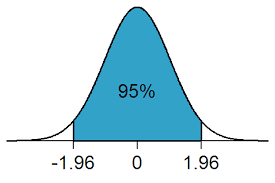
محققان معمولا به دنبال نشان دادن صحت تئوری مطرح شده توسط خود هستند، ولی وقتی مقدار P-value محاسبه می شود تنها می توان راجع به داده ها صحبت کرد. این مهم است که بدانیم که P-value به احتمال مشاهده داده ها مربوط است و ارتباطی با احتمال درست بودن یک تئوری ندارد. بنابراین می توان P-value را این گونه تفسیر کرد که داده های مشاهده شده تا چه میزان با فرض صفر مطرح شده همخوانی دارند. مقادیر پایین P-value به معنای عدم وجود همخوانی و مقادیر بالای آن به معنای وجود همخوانی بیشتر است. به همین دلیل است که مقادیر پایین P-value باعث رد کردن فرض صفر می شود و مقادیر بالای آن به معنای عدم توانایی در رد کردن فرض صفر خواهد بود. برای درک بیشتر به شکل زیر توجه کنید.
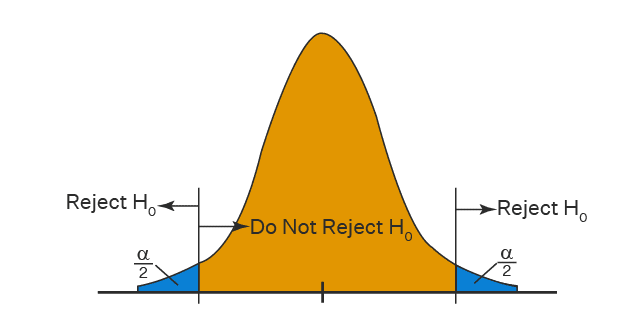
برای تفسیر P-value از سطح معنی داری استفاده می شود. اگر  باشد می توان فرض صفر را رد کرد و این به معنای وجود تفاوت آماری معنادار بین گروه ها می باشد. در مثال مطرح شده در ابتدای بحث می تواند به معنای تغییر سرعت متوسط خودروها پس از اعمال اصلاحات لازم باشد. اما اگر رابطه
باشد می توان فرض صفر را رد کرد و این به معنای وجود تفاوت آماری معنادار بین گروه ها می باشد. در مثال مطرح شده در ابتدای بحث می تواند به معنای تغییر سرعت متوسط خودروها پس از اعمال اصلاحات لازم باشد. اما اگر رابطه  برقرار باشد، نمی توان فرض صفر را رد کرد و می توان آن را این گونه تفسیر کرد که تفاوت معنادار آماری بین گروه ها وجود ندارد. لازم به ذکر است که عدم رد شدن فرض صفر به معنای عدم وجود تفاوت نیست و ممکن است با در اختیار داشتن تعداد نمونه بیشتر بتوان فرض صفر را رد کرد.
برقرار باشد، نمی توان فرض صفر را رد کرد و می توان آن را این گونه تفسیر کرد که تفاوت معنادار آماری بین گروه ها وجود ندارد. لازم به ذکر است که عدم رد شدن فرض صفر به معنای عدم وجود تفاوت نیست و ممکن است با در اختیار داشتن تعداد نمونه بیشتر بتوان فرض صفر را رد کرد.
منابع:
p-values: What they are and how to interpret them
Null Hypothesis, p-Value, Statistical Significance, Type 1 Error and Type 2 Error
Improving your statistical inferences
Roess, R. P., Prassas, E. S., & McShane, W. R. (2004). Traffic engineering (pp. 1-99). Pearson/Prentice Hall
پاسخها